
NHK「きょうの料理」のレシピ分析:機械学習による人気レシピの予測と新レシピ生成
ご存じの方も多いと思いますが、「きょうの料理」はNHK Eテレで放送されている料理番組です。紹介されたレシピはWEBサイト「みんなのきょうの料理」へ掲載され、誰でも参照することができます。本記事では、「みんなのきょうの料理」から収集したレシピ情報を分析した結果について紹介します。
1. 分析の背景と方針設定
筆者自身が料理番組やレシピサイトを参照する際の目的は、人気の新しいレシピを知ること、冷蔵庫にある食材で作れるレシピを知ること、の2つあります。そのため、分析においては次の2つの方針を立てました。
1)人気レシピの要素を探索するために、「マイレシピ登録数」を目的変数として、機械学習で予測をする。
2)レシピの学習結果を基に、指定した材料名を用いた新しいレシピを生成する。
2. データについて
2-1. データ収集
レシピ中の以下の項目をサイトからWEBスクレイピングで収集し、データフレームを作成しました。
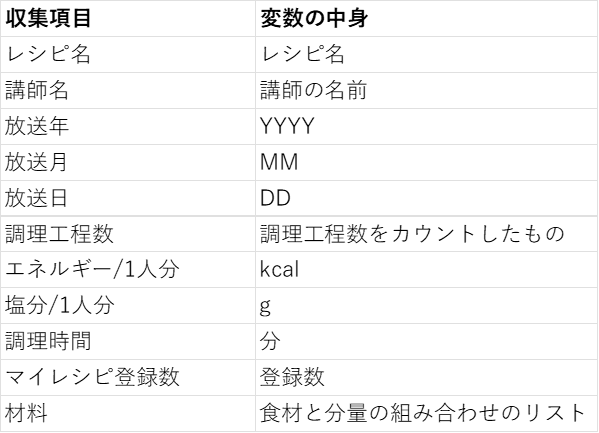
収集したのは2023年12月で、データの対象年は2001から2023年、サンプルサイズは18413となりました。
2-2. 特徴量の追加
カテゴリカル変数である「講師名」と「材料」は以下の通りエンコーディングをしました。
「講師名」=講師の登場回数 (講師毎のレシピ数) を数えるカウントエンコーディング。
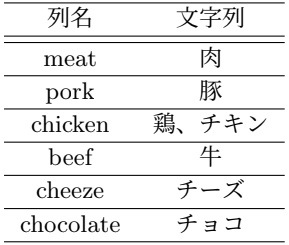
「食材名」= 肉、鶏、豚、牛、チーズ、チョコレートを対象として、ワンホットエンコーディング。「材料」列に対して形態素解析を実行し、表で示した文字列が存在するか否かを識別。
3. マイレシピ登録数の予測について
3-1. 仮説設定
各変数の特徴に基づき、2つの仮説を立てました。
仮説(1) マイレシピ登録数に「講師」が影響を与えている。
レシピが掲載されている講師は631人いますが、講師毎の掲載レシピ数は大きく偏っています。また、以下は、講師毎のマイレシピ登録数の合計をヒストグラムで表した結果です。合計登録数の多い講師順にその合計登録数を足していき、上位 50%の講師のみを表示しています。
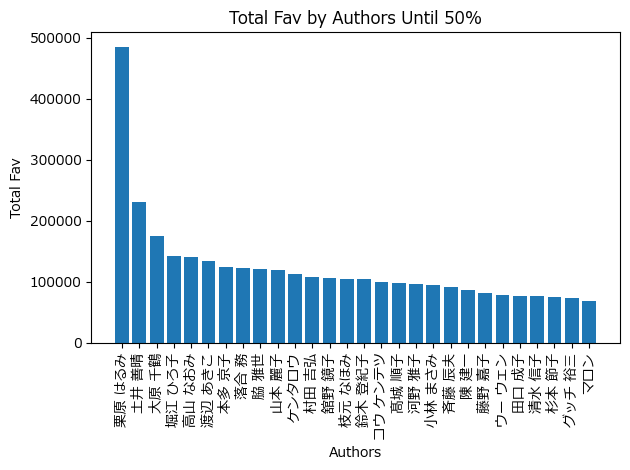
28人の講師によってマイレシピ登録数合計の半数が占められていることが分かりました。よって、人気の講師がより多くのマイレシピ登録を獲得している、と推測しました。
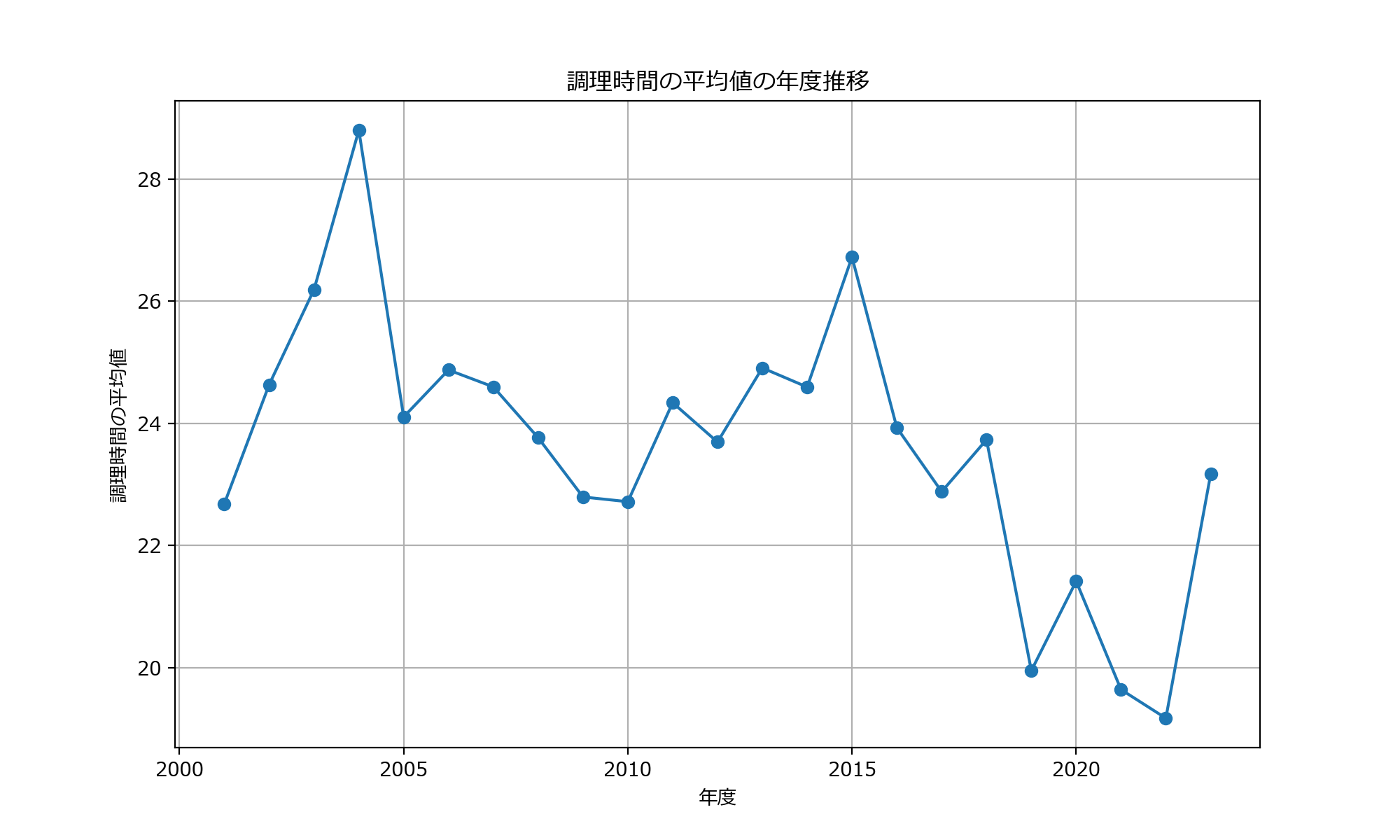
仮説(2) マイレシピ登録数に「調理時間」が影響を与えている。以下に平均調理時間の年度推移を示しています。年ごとに上下動はあるものの、全体として減少傾向であることが分かります。そのため、近年はより調理時間の短いレシピが好まれるようになってきたと推測できます。
3-2. 機械学習と予測
機械学習で用いた変数は以下の通りです。
予測モデルはランダムフォレストリグレッサーを、予測精度の確認には平均二乗誤差を用いました。またハイパーパラメータを調整し、データは8割を訓練用、2割をテスト用として準備しました。
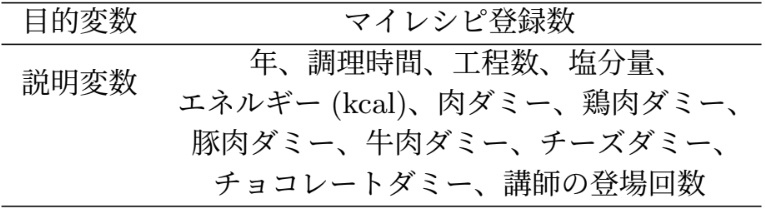
予測における特徴量の重要度は以下のようになりました。仮説(1)の通り、講師がマイレシピ登録数に影響を与えている影響が高いと示唆されますが、仮説(2)は立証されませんでした。
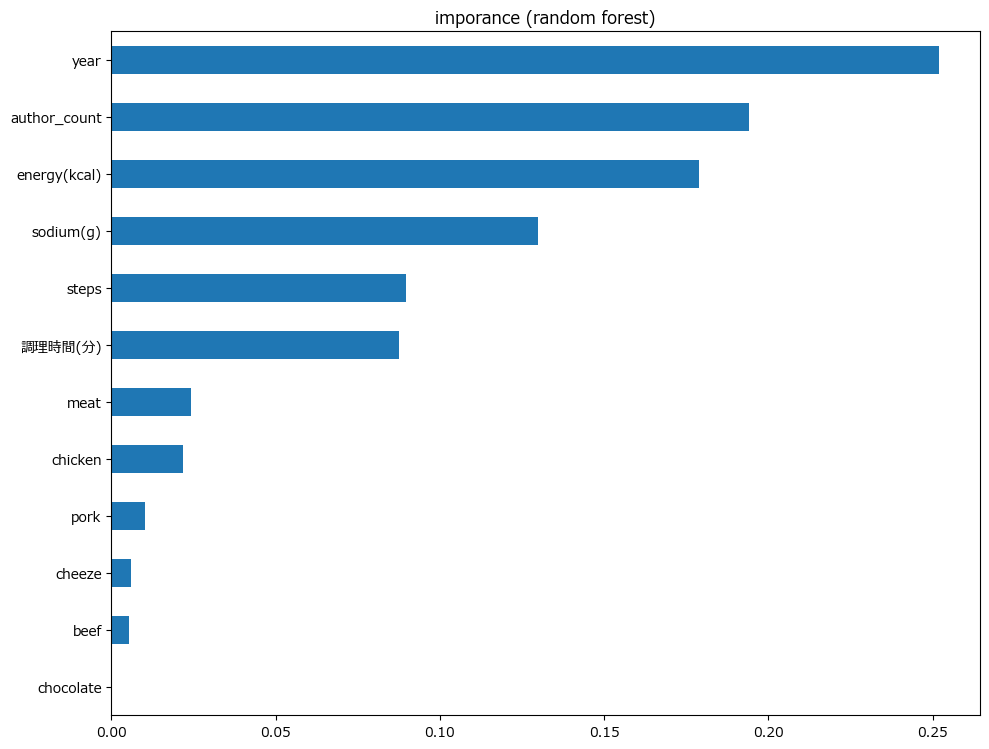
参考)Random Forest予測結果
尚、平均二乗誤差は459923と、精度が良かったとは言えません。検証はしていませんが、今回用いなかった食材や「講師×食材」といった交差項を変数として追加することで精度が上がるかもしれません。
4. 新レシピの生成
4-1. レシピの生成方法
以下の流れで、レシピ名と材料名を生成しました。
(1) レシピ名の生成
① データフレームの「レシピ名」列をTokenizerを用いて分かち書きし、列に追加。
② 「recipe_wakati」列をtri-gramで学習。
③ 任意の食材名から始まるレシピ名をランダムに生成。
(2)材料の出力
① 「材料」列をbi-gramで学習
② (1)の③で生成したレシピ名中の食材名で「材料」列を検索し、合致したらその食材を材料とする。
③ (2)の②で抽出した材料に対応する分量を(2)の①で学習したモデルに基づき生成する。
今回指定した食材は、「パン」、「鶏」、「なす」「オレンジ」の4つです。炭水化物、メインの肉料理、サイドメニューの野菜料理、デザートの 4 種類を含む1 回の食事をイメージしました。
4-2. レシピの生成結果
結果、このような怪しいレシピが生成されました。

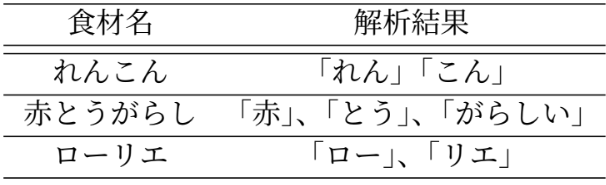
レシピ生成における課題は、次の3点です。1つ目は、形態素解析が正しくなされないことです。例えば、以下の表のような解析がなされてしまいました。
2つ目は、チャーハンとせんべい汁が一つの料理になってしまうなど、実際にはありえない食材の組み合わせが出力されてしまったことです。3つ目は、レシピ中の食材名が、材料に正しく反映されていないことです。いずれも、食材名の辞書を準備することや、料理のカテゴリ、食材の組み合わせの傾向も合わせて学習させるなど、学習方法を改善させる必要があると考えられます。
5. 終わりに
筆者自身はデータサイエンス初学者だったので、精緻な分析というよりも何か面白いことをしたい、と考えて取り組んでいました。結果、予想もしていなかった面白い(≒怪しい)レシピと巡り合えたとともに、日本語における形態素解析の難しさや、思い通りに機械学習させる難しさを学ぶことができました。
データサイエンスやプログラミングは何か難しそう、と思うかもしれませんが、とりあえずやってみようの精神で取り組んでみると、面白いことに出会えると思います。
参考文献
日 本 放 送 協 会 (2023)「 こ の 番 組 に つ い て 」https://www.nhk.jp/p/kyounoryouri/ts/XR5ZNJLM2Q/(閲覧日:2023 年 12 月 28 日)
株 式 会 社 NHK エ デ ュ ケ ー ショ ナ ル (2023)「 ご 利 用 に あ た って」,https://www.kyounoryouri.jp/contents/about/(閲覧日:2023 年 12 月 28 日)





