Visualizing All Kanji in a Graph
In the previous articles about leveraging ChatGPT for kanji study, we encountered the issue that ChatGPT does not know how kanji look like visually. However, this is important to provide help with memorizing kanji.
Ideally, ChatGPT should know which components a kanji is made of, then it can also tell us which kanji look similar.
While computer vision approaches are a possible solution, I want to introduce a different, graph-based, approach. Jitenon is an online kanji dictionary page that provides information on kanji components, and also stroke count, level and readings.
Identifying visually similar kanji
Let’s begin by looking at some examples.
The kanji「時」is definitely similar to「寺」, which is its major component. It is especially helpful to know because they have the same on-yomi: じ. Similarly,「待」and「持」share the same major component but differ in radicals.
This is also important to know in order not to confuse the kanji. The different radicals also give a clue on the meaning:「時」has something to do with time, whereas「持」has something to do with using your hand.
To systematically explore these relationships, we construct a directed graph from the information obtained from Jitenon, where each kanji or component forms a node, interconnected by “is_component_of” relationships as edges.
The code is available in our GitHub repository. The code for the scraper is available from the author upon reasonable request.
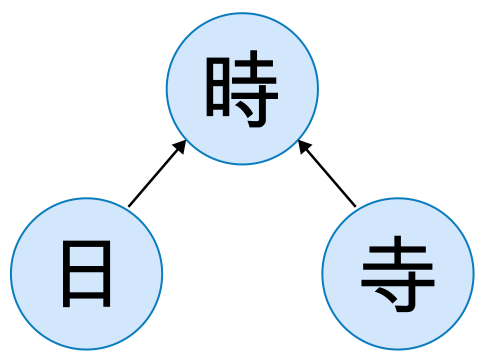
Basic structure of the directed graph with “is_component_of” relations.
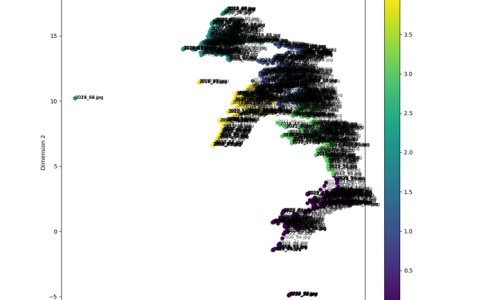
Jitenon contains more than 10.000 kanji and radicals. Using the graph visualization tool Gephi, we show a subset of 3000 kanji and 500 corresponding radicals in a graph:

Graph including 3000 kanji and 500 radicals. Kanji are connected to their components. Kanji with a higher degree (number of connections) are larger and purple.
I personally find it a bit unreal to have all kanji laid out like this. It also makes you think twice before you learn this language. You can see that certain components occur in a lot of kanji, e.g.「木」and「口」.
It might be a good strategy to start learning the kanji that often occur as components in other kanji.

Kanji containing the radical「扌」, visualized in Gephi. 
Kanji containing the component「木」, visualized in Gephi.
Next, how can we use this graph to identify similar kanji? We want e.g.「時」and「寺」to be classified as similar, but not「明」. Therefore, it seems like a good idea to get the largest component(寺)as well as its successors in the graph, i.e. all kanji that contain this component. This is easy since Jitenon also includes the number of strokes for each component.
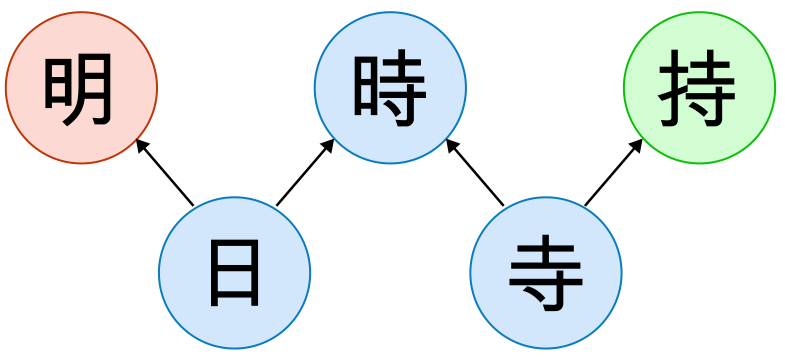
Schematic illustration of similarity relations. 「明」(red) only shares the smaller radical and is not similar enough.
Let’s see this in action. The implementation can be found here. The following is a list of all kanji that include the component「寺」:
| 詩: [‘シ’], [‘うた’] 待: [‘タイ’], [‘ま(つ)’] 持: [‘ジ’, ‘チ’], [‘も(つ)’] 等: [‘トウ’], [‘ひと(しい)’, ‘など’, ‘ら’] 特: [‘トク’, ‘ドク’], [‘おうし’, ‘とりわ(け)’, ‘ひと(つ)’, ‘ひと(り)’] 侍: [‘ジ’, ‘シ’], [‘さむらい’, ‘さぶら(う)’, ‘はべ(る)’] 畤: [‘シ’, ‘ジ’], [‘まつりのにわ’] 恃: [‘シ’, ‘ジ’], [‘たの(む)’] 峙: [‘ジ’, ‘チ’], [‘そな(える)’, ‘そばだ(つ)’, ‘たくわ(える)’] 痔: [‘ジ’], [‘しもがさ’] 邿: [‘シ’], [] |
As you can see, this method works equally well for the rarer component「司」, where ChatGPT failed.
| 飼: [‘シ’], [‘か(う)’, ‘やしな(う)’] 伺: [‘シ’], [‘うかが(う)’] 嗣: [‘シ’], [‘つ(ぐ)’] 祠: [‘シ’], [‘ほこら’, ‘まつ(り)’, ‘まつ(る)’] 笥: [‘シ’, ‘ス’], [‘け’, ‘はこ’] 覗: [‘シ’], [‘うかが(う)’, ‘のぞ(く)’] 鉰: [‘シ’], [] |
We can even filter for kanji we already know, using the level information.
Now we can make use of this information in ChatGPT, by either using the API or manually copying this output over.
Of course this is still not perfect, as it does not distinguish between positions of the components. We could get a more accurate result by using node2vec or a graph neural network to really find the most similar kanji, since the similarity is encoded in the connections.
We can also extract only the unknown words from a text by filtering for kanji with certain difficulty. Let’s use the following text from a book:
紀伊半島中央部、連綿と続く山稜の奥にたたずむ玉倉山。その山上に位置する玉倉神社の生活が、今ではかなり身についてきた。以前から順応性は高いほうなのだ。朝、深山に響く鳥の声で目覚めるという、仙境のような暮らしぶりもそれなりに悪くなかった。
Setting the minimum level to 5 (roughly corresponds to 5th grade) yields the following words:
| 紀伊 山稜 奥 響く 仙境 暮らし |
See here for an end-to-end implementation that extracts words from a text and utilizes ChatGPT to create a kanji worksheet.
It uses the SudachiPy package to identify and normalize words.
Conclusion
We have seen that a graph-based approach is indeed useful in identifying similar-looking kanji, and demonstrated some example use cases for learners. Since LLMs are computationally expensive, it is important to consider alternative solutions.
東京大学 羽室開
[date] 2024-02-03
[upload] 2024-05-15
Enhancing Japanese Study with ChatGPT – Part I
Enhancing Japanese Study with ChatGPT – Part II