生成AIと著作権に関するパブリック・コメント:ChatGPTを用いた分析
1 はじめに
(1)生成AIの社会的重要性
インターネットの普及やコンピュータの計算能力向上などに伴い、近年は人工知能(AI)技術の開発が加速しています。中でも、生成AIが顕著な進展を遂げており、その活用可能性が期待されています。AIに特別詳しい人でなくとも、朝のニュース番組で原稿の一部がAIによって読み上げられたり、AIが描いたイラストや声優さんの声を無断で利用したAIカバーが世の中に出回ったりと、人々にとって生成AIの存在が身近になってきたように思います。
生成AIは画期的な発明であって我々の生活を豊かにする一方で、著作権の問題や、偽情報の拡散、倫理的な使い方といった、更なる問題を引き起こす危険性も孕んでいます。
(2)著作権に関する問題
本記事では、筆者がロースクール生であって、法律問題に関心が高いことから、生成AIと著作権に関する問題を取り上げたいと思います。
(ア)著作権とは
著作権は、著作権法によって定められています。同法は、著作物の「公正な利用に留意」しつつ、「著作者等の権利の保護」を図ることで、新たな創作活動を促し、「文化の発展に寄与すること」を目的としています。
著作権侵害が成立するためには、「後発の作品が既存の著作物と同一、又は類似していること」、つまり類似性と、後発の作品が「既存の著作物に依拠して複製等がされたこと」、すなわち依拠性が必要となります。具体的には、著作権者の許諾なしに著作物を利用した場合、これらの要件を満たすことで著作権侵害とされることになります
[1]。
(イ)生成AIに対する法整備
生成AIに限らず、著作権法の解釈は、本来、保護の対象となる著作物ごとに個別具体的に判断されます。しかし、現在、生成AIと著作権について正面から検討された判例及び裁判例の蓄積が少なく、生成AIの特徴を踏まえた特別の立法もなされていません。
したがって、生成AIと著作権の問題を法的に捉えるに当たり、現在の法制度や社会状況についての大衆の考えを知る必要があるのではないかと考えました。
2 用いるデータと分析の目的
文化審議会著作権分科会法制度小委員会(以下「本委員会」という。)[2]は、行政運営の公正さの確保と透明性の向上を図り、国民の権利利益の保護に役立てる目的で、AIと著作権に関する考え方ついて広く一般から意見(パブリック・コメント)を募りました。この寄せられた意見につき、文化庁がまとめた資料(「AI と著作権に関する考え方について」(素案)に関する意見募集に寄せられた主な意見)と回答者の回答データそのもの(「AI と著作権に関する考え方について(素案)」のパブリック・コメントの結果について(個人)その1〜3)(以下、「本件データ」と呼ぶ。)が公開されています[3]。
そこで、本記事では、人々の生成AIと著作権に対する意見を俯瞰するために、自然言語処理技術を用いた本件データ(生成AIに関するパブリック・コメント2998件)について行った分析を紹介します。文化庁の資料ではなく本件データを分析対象としたのは、人々の認識と要望・規範的主張など、意見者のものごとの捉え方を直接的に分析するためです。
本件データを肯定的な意見と否定的な意見に振り分け、その分布をみた後に、それぞれの特徴を捉え、両者を比較しました。これによって、生成AIと著作権に対する社会の見解を把握し、今後の生成AIの法整備について考察します。
3 手法
(1)極性分布:ChatGPT
第一に、二つのモデルを用いて極性分布(肯定的な意見と否定的な意見の分布)を調べました。本レポートでは、まずjarxisx17モデル[4]を用いて実験することにしました。しかし、軽量な深層学習であるため512文字しか入力することができませんでした。これでは回答文章全体に対する分析が行えません。
そこで、全文を分析可能なChatGPTを用いることとしました[5]。具体的なプロンプトは次になります。
|
使用したプロンプト |
|
次の文章には、生成AIの規制に関する意見が含まれています。この文章の筆者の意見が生成AIに対して肯定的、中立的、または否定的であるかを数値で評価してください。肯定的であれば1、否定的であれば0に近づくように数値を設定してください。
以下のJSON形式で回答してください。説明は入れずに、このフォーマットのみで回答してください。 {“極性“:“0.2”} === |
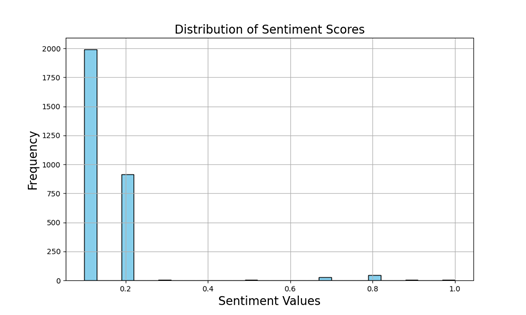
図1. パブリック・コメントの極性分布
図1にChatGPTで調べた極性の分布をヒストグラムとして可視化しました。X軸において、生成AIと著作権に対する捉え方を数値化し(否定的なものを0、肯定的なものを1とした)、Y軸において、要素の個数を数えました。
図1からは、明らかに生成AIと著作権について否定的な考えを持つ者が多いことがわかります。また、否定とも肯定ともいえない立場の人は少なく、肯定的に捉える者が全くいないわけではないことも読み取れます。本データが社会における生成AIに対する意見の極性分布を正確に捉えているかどうか、あるいは別の言い方をすれば、社会全体の意見を代表する標本調査になっているかに関しては議論の余地がありますが、本記事ではこのデータを用いて生成AIに対する肯定的な意見と否定的な意見の差を分析してみます。
(2)文章の分析:3段階のChatGPT
(ア)意見の構造化
一言に、文章を分析するといっても、本委員会は自由形式でパブリック・コメントを回収しているため、そのままではChatGPTがどのように意見を振り分けるか判断することができません。
そこで、一度文章全体を構造化し、捉え方をパターン化するアプローチを採用しました。具体的には図2のような関係図を意識して意見を構造化しました。
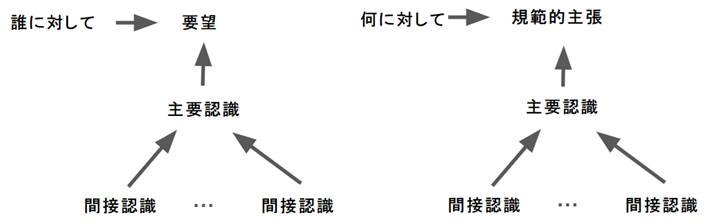
図2. パブリック・コメントの意見構造
(イ)第1段階
この関係図を念頭に第1段階としてパブリック・コメントの中の文を次の4つのパターンに分類してみました。
・Pattern1: 「誰が, 何に対して, どうあるべきである」という規範的主張
・Pattern2: 「誰が, 誰に対して, どうして欲しい」という要望
・Pattern3: 「何が・誰が、何に対して、どういう状況を引き起こしているか」という因果関係
・Pattern4: 「誰が, 何に対して, どう捉えているか」という認識
ChatGPTに一度に聞くと本来ならば上記のパターンに分類できる場合でもいくつか文を飛ばす傾向にあることがわかりました。そうした不具合が起こらないように、またさらに気がついた細々とした点を修正するために、以下五点の工夫を施しました。
①指示語を置き換え、言い換え表現を出力したこと
②意見全てをいきなり投入するのではなく5文ずつにわけて抽出したこと
③繰り返し、「できるだけ元の表現をそのまま使うようにし、勝手に文章に書いてある表現を変化させないようにしてください」と注意したこと
④出力結果のエッジリストには元の文章に存在しないフレーズが含まれていないことを確認し、元の文章にないフレーズの出現回数が0であることを保証させたこと
⑤分析しやすいようにjson形式で出力させたこと
⑥この時点での出力例は図3のようになります。

図3:第1段階の出力例
(ウ)第2段階
Pattern1からPattern4まででは図2に記した要望や規範的要件を分析できていません。そこで第2段階では要望や規範的要件と直接関係する認識を探し出し、それを支える間接認識を導くために、上記基本4パターンに対し、さらに下記枠組みを抽出しました。
・Pattern5: 因果関係(Pattern3)や認識 (Pattern4) が他の要素 (Pattern1の規範的主張、Pattern2の要望) に影響を与えている場合の関連性
Pattern5の抽出に関しては各意見に対して第1段階で抽出したPattern1からPattern4と元の文を両方入力とした上でPattern5を抽出するように指示を出しました。また、第1段階の時の工夫に加えて、以下二点の工夫をしました。
⑦指定したエッジリストの形式よりも要素数の多いタプルなど形式を守っていないものを出力しないこと
⑧全てのPattern1とPattern2について、それぞれの対応関係を見つけ、Pattern1の規範的主張やPattern2の要望が存在しない場合、エッジリストは空で返すことの指示を追加した
参考までに図4に第2段階の出力例を掲載しておきます。

図4:第2段階の出力例
(エ)第3段階
以上の手順だけでも分析ができる結果は出力されていますが、このままの形式だと各抽出文が長い上に、それぞれの要素の関係性を一目で把握することができず分析しにくいため、再度ChatGPTを使って、出力データを文章化させました。
具体的には、Pattern5によって、各要素の対応関係が明らかになったため、「AがBであるから、CはDであるべきである」又は「AがBだから、Eに対してFをして欲しい」の形に各要素を10文字以内でまとめるよう指示を出しました。このとき、ChatGPTが例文を使って勝手に文章を創作してしまわぬよう、意図的に論旨不明な文章を出力例として挙げ、誤りがあった場合にそれが明白にわかるよう工夫しました。
このようにして抽出したAからFまでの各出力結果を、まずはUniversal Sentence Encoder[6]でベクトル埋め込みに変換し、次にDBSCAN[7]を用いクラスタリングをすることで、同じ意味内容のものを一つにまとめました。最終的にA,B,C,D,E,Fは図5のように出力され、グループ化された(名寄された)番号をA_c,B_c,…と記しました。
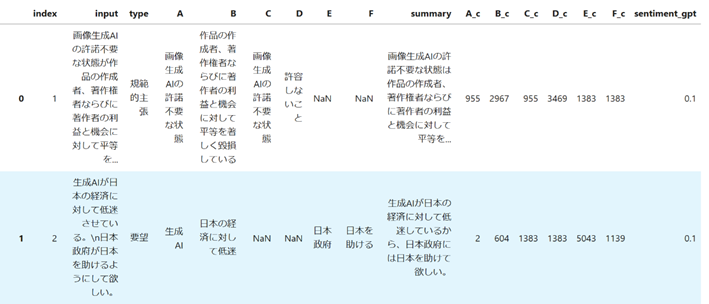
図5:第3段階の出力例
4 結果
肯定派と否定派とに分けて、意見者のものごとの捉え方を抽出し、ネットワークを用いて可視化を行い、それぞれの特徴を考察していきます。
ChatGPTを用いた要約結果をデータフレームにして、さらに、Pattern5で明らかになった関連性をGephiというネットワーク描画ソフトウェアを用いて描画しました。このとき、前節で作成したノード(同じ表現をひとまとめにしたグループ)を用い,A=>B,B=>C,C=>DあるいはA=>B,B=>E,E=>Fを繋ぎ、ネットワーク全体としては次数2以上のエッジにのみ絞り、ポジティブなものに関しては件数が少ないので次数が1でもよいとして、エッジの変化に関心を絞りました。
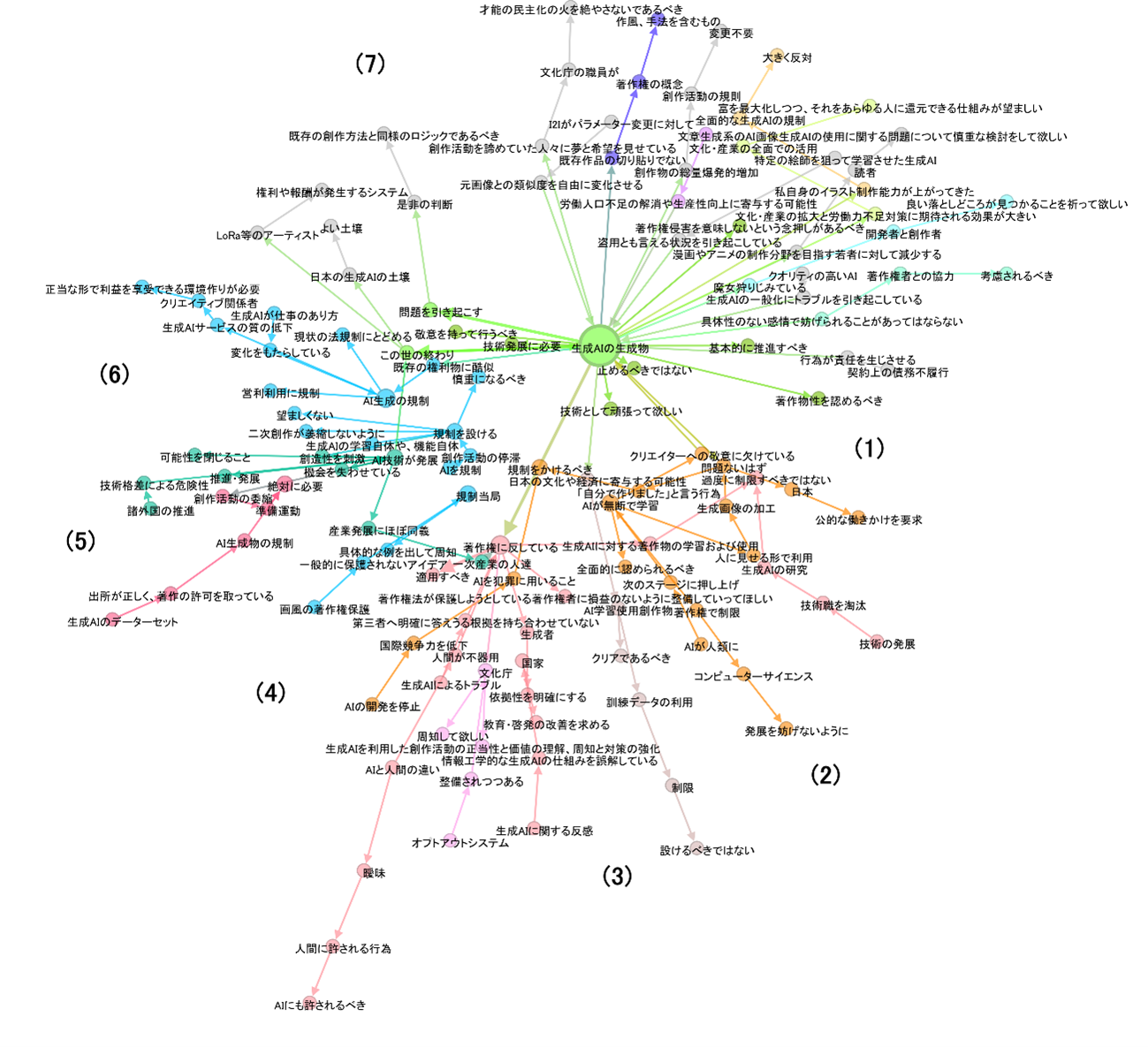
ノードは、肯定派であっても、否定派であっても同じ位置に描画されるように工夫しました。これによって類似する問題に対して、肯定派と否定派の意見がどのように異なるかについての視認性を高めることができます。以下では、全体のネットワークを(1)から(7)までのノードに分けて、各位置でどのように主張が異なっていたかを見ていきます。
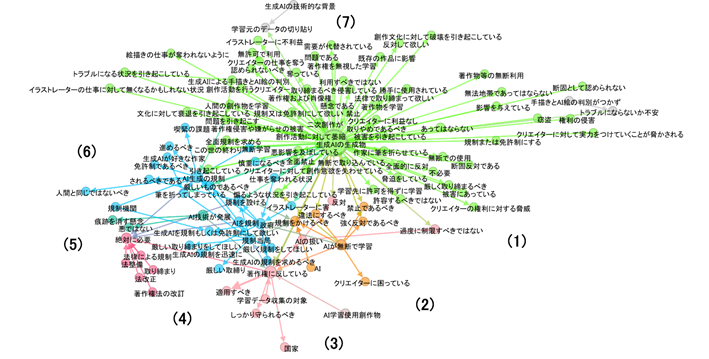
図6:否定的な意見

図7:肯定的な意見
表1に(1)から(7)までの各位置における肯定派と否定派の特徴をまとめました。表1に記載した軸となるノードとは、肯定派と否定派のものごとの捉え方の違いが顕著に異なっているノードのことをいい、図6と図7を見比べて筆者が見つけました。それらのノードを中心にネットワークを辿ると、両者の意見の違いが見やすくなると思います。
|
位置 |
軸となるノード |
肯定派 |
否定派 |
|
(1) |
「生成AIの生成物」「過度に制限すべきではない」 |
「生成AIの研究」に対して「過度に制限すべきではない」という意見を軸に「日本」に対して「公的な働きかけ」を要求している点や「AIが無断で学習」することを「クリエーターへの敬意に欠けている」としつつも「生成AIの生成物」に対しては「止めるべきではない」や「著作物性を認めるべき」など寬容な意見が目立つ。否定派のように強固に反対している意見が見られない。 |
「AIの扱い」について「過度に制限すべきではない」とあるものの「生成AIの生成物」に対して「許容するべきではない」や「脅迫をしている」など強固に反対している意見が目立つ。 |
|
(2) |
「AIが無断で学習」 |
「AIが無断で学習」することに対して「全面的に認められるべき」とあったり「著作権での制限」に関しても「コンピューターサイエンス」の「発展を妨げないように」など新しい技術に対して肯定的な意見が目立つ。 |
「AIが無断で学習」することに対して「クリエイターに困っている」という意見や「強く反対であるべき」などの否定的意見が多い。 |
|
(3) |
「AI学習使用創作物」 |
「AI学習使用創作物」に対して「訓練データの利用」に関して「制限」を「設けるべきではない」と、クリエイターというよりはエンジニア側の視点に立った意見を述べている。 |
「AI学習使用創作物」に対して「著作権に反している」と厳しく批判している。 |
|
(4) |
「規制当局」 |
「規制当局」に対して「具体的な例を出して周知」して欲しいと要望を述べるなど生成AIユーザー側にたっている。 |
「規制当局」に対して、「著作権に反している」から「規制当局」に対して「AIを規制」して欲しい「生成AIを規制もしくは免許制にして欲しい」「厳しい取り締まりをしてほしい」と規制強化の意見を強く述べている。 |
|
(5) |
「AI技術が発展」 |
「AI技術が発展」に対して「産業発展にほぼ同義」であるとか近くに「諸外国の推進」が「技術格差による危険性」につながるなど経済発展に関連させた議論が目立つ。 |
「AI技術が発展」に対して「痕跡を消す懸念」につながっている。 これは著作権法の依拠性の根拠となる痕跡を消せてしまう可能性について言及しており、その点でさらなるAI技術の発展によって現行法制度が形骸化するのではないかという懸念を示したものである。 |
|
(6) |
「AI生成の規制」 |
「AI生成の規制」に対しては「現状の法規制にとどめる」や「営利利用に規制」するなど現状維持の意見が目立つ。 |
「AI生成の規制」に対して「免許制であるべき」「厳しいものであるべき」「人間と同じではないべき」などの積極的に規制する方向の意見が目立つ。 |
|
(7) |
「生成AIの生成物」 |
「生成AIの生成物」に対して,「才能の民主化の火を絶やさないであるべき」「富を最大化しつつ,それをあらゆる人に還元できる仕組みが望ましい」「生成AIの仕様に関する問題について慎重な検討をして欲しい」「創作活動を諦めていた人々に夢と希望を見せている」「良い落としどころが見つかることを祈って欲しい」など,新しい技術を有効活用しようという期待が述べられている。 |
(1)と同様に「創作文化に対して破壊を引き起こしている」「窃盗」「クリエイターに対して実力をつけていくことが脅かされる」など強固に反対している意見が目立つ。むしろ,最大次数ノードである「生成AIの生成物」に対して,直接的に批判的な思いがこの位置にまで広がっている。 |
表1:各位置における否定派と肯定派の意見の違い
表1からは、論点ごとに肯定派と否定派でものごとの捉え方が異なることが読み取れます。位置(3)・(4)に見られるように、肯定派は生成AIのユーザーやエンジニア寄りの意見が目立つのに対して、否定派はクリエイターを擁護する側にたっている意見が多いです。また、位置(4)・(6)に表れているように肯定派が法制度に関しては現状維持を希望しています。日本の著作権法が2018年から2021年にかけて4回改正され、特に2018年の改正では、研究や技術開発のための著作物利用が無許諾で可能となり、AIの学習が容易になりました (第30条の4,第47条の4,第47条の5)。かかる法改正が社会にいかなる影響を与えたかは分からないものの、現在の法制度が機械学習応用に対して一定の理解を示していることから、肯定派が現状維持を望んでいる可能性があります。他方で、反対派は「AI生成の規制」に対してさらに積極的に規制するように求める意見が目立ちます。さらに(1)と(7)のように反対派は「生成AIの生成物」を中心に「許容するべきではない」「脅迫をしている」「創作文化に対して破壊を引き起こしている」「窃盗」「クリエイターに対して実力をつけていくことが脅かされる」など強固に反対している意見が数多くあります。その結果として「生成AIの生成物」が最大次数のノードになっています。(2)と(5)の肯定派の意見も興味深く、(2)においては「コンピューターサイエンス」の「発展を妨げないように」など新しい技術に対して肯定的な意見がある一方で、(5)では「AI技術が発展」に対して「産業発展にほぼ同義」とあるなど技術発展や経済発展と関連付けた議論があります。
このように、意見の階層構造を意識してパブリック・コメントから主要な主張を抽出することによって、生成AIに対する否定派と肯定派のナラティブ構造の違いを比較・分析することができました。
5 まとめ
本記事では、LLMsを活用し、書き手の論旨構造を階層的に整理するとともに、文の属性情報を用いて話者間の違いをネットワーク分析によって可視化する提案方法を紹介しました。提案手法は,人や関係性,時といった物語としてのナラティブ構造とは異なり,パブリック・コメントや判決文のように意見構造が明確に存在する文書に適していると考えられます。
以下では、分析方法と得られた結果に対する感想、及び今後の展望について、簡単に述べていきます。
(1)分析方法
分析時に①パブリック・コメントの文章に構造を見つけたこと、及び、②この構造に基づいて文章を可視化したことによって、不揃いな文体、かつ、膨大な量の本件データの分析を比較的容易にしたと考えます。具体的には、①によって、文章の形式が統一され、各文章を比較しやすくなり、②によって、否定派と肯定派それぞれの全体像が明確になり、横断的な分析が可能になったのではないかと思いました。
反省点としては、法制度・法律に対する意見とその他一般的事実レベルの意見が混在することを考慮しきれなかったことが挙げられます。事前に両者を振り分けた上で、段階的に分析をした方が、より精度の高い結果を得ることができたように思います。
(2)結果
特に興味深かったのは、一見法律とは無関係に思えても、著作権侵害の要件に照らして注意深く考察すると、実は要件に関わる可能性を指摘する意見の存在を発見できたことです(図3(5))。パブリック・コメント制度を通じて、法制度の賛否を論ずるのではなく、潜在的な論点について言及する意見の回収も可能であることに気付かされました。
(3)今後の展望
以上を踏まえても、現在、生成AIと著作権につき否定的な意見に大きく傾いているという結論が左右されることはありません。また、抽象的な事実を捉えて、極端に否定的な意見を述べる者が多いことから、人々がAIの利便性や危険性について十分に理解する前に、劇的に技術が発展し、我々の生活に影響を与えるようになったために、得体の知れないもの(AI)に怯える者が多いのではないかと考えました。したがって、人々に新技術の安全性を周知した上で、生成AIを介さない生成物や既存のクリエイターの権利の保護のために、慎重かつ確実に法整備を進めるべきであると考えました。
6 おわりに
データサイエンスについて右も左もわからない中、東京大学大学院情報理工学系研究科 久野先生には、指導教員として終始熱心なご指導を賜りました。心から感謝いたします。
また、終始温かいご助言を頂いた同研究科近藤先生、TAの松本さん、弁護士の吉田先生、渡辺先生にも大変お世話になりました。御礼申し上げます。
本記事の詳細は論文に記載されています。
Hierarchical Narrative Analysis: Unraveling Perceptions of Generative AI(情報処理学会 人文科学とコンピュータシンポジウム 「じんもんこん2024」採録)
参考文献
[1]https://www.bunka.go.jp/seisaku/chosakuken/pdf/93903601_01.pdf
[2]https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/hoseido/r05_07/
* レポート提出時点では(3)まででしたが、その後(4)(5)(6)が追加されました。本件に対する関心の高さが伺えます。
[3]https://huggingface.co/jarvisx17/japanese-sentiment-analysis
* 全ての実験はChatGPT(gpt-4-turbo-2024-04-09)で行いました。
[4]Cer, D., Yang, Y., Kong, S., Hua, N., Limtiaco, N., St. John, R., Constant, N.,
Guajardo-Cespedes, M., Yuan, S., Tar, C., Strope, B., & Kurzweil, R.
(2018). Universal Sentence Encoder for English. In Proceedings of the 2018
Conference on Empirical Methods in Natural Language Processing: System
Demonstrations (pp. 169–174). Brussels, Belgium: Association for Computational
Linguistics.
[5]Hahsler, M., Piekenbrock, M., & Doran, D. (2019). “dbscan: Fast
Density-Based Clustering with R.” Journal of Statistical Software, 91(1),
1-30.
以上
東京大学大学院法学政治学研究科
2024年11月7日 松岡季音声





