
意味をつなぐ、知識を紡ぐ:LLMsによる知識グラフ精緻化の試み
1.はじめに
大規模自然言語モデル(Large Language Models、LLMs)に単純に問いかけるだけでは、専門知識に関する幻覚が生じやすい問題がある。この課題を解決するため、RAG(Retrieval Augmented Generation)と呼ばれる手法が開発された。RAGでは、大量の文書データを別に用意し、プロンプトに関連する内容を持つ文書を参照することで回答の精度を高める。この考え方を検索エンジンと組み合わせて実現しているのが、Perplexityや最近のChatGPTである。これらのサービスは、インターネット上から関連性の高い文書を取得・整理し、それを基に回答を生成することで幻覚の問題を効果的に抑制している。従来の検索エンジンでは、キーワードを入力した後、一つ一つのウェブサイトにアクセスし、時には広告だらけのページを探索しながら必要な情報を見つけ出す手間があった。これに対して、AIが必要な情報を自動的に要約してくれる利便性に触れたとき、技術の進歩に筆者も感銘を受けたものである。
しかし、単に文書をいくつか拾い、それに基づいて答えるだけでは、専門知識に含まれる複雑な構造を捉えきれないことがある。文書同士にもつながりが存在し、いくつか選んだ文書をもとに生成するだけでは、そうした関係性を無視することになる。これを補うために生まれたのがGraph RAGである。Graph RAGは、単なる文字列の集まりではなく、知識同士が論理的につながるようにグラフ構造やナレッジグラフとして情報をあらかじめ整理し、その構造を活用してより確かな生成を目指す手法となる。実は知識をグラフ構造で結びつけるという分野自体、インターネットの黎明期から存在しており、それはセマンティック・ウェブと呼ばれてきた。セマンティック・ウェブとは、一般的にウェブ上の情報に意味づけを行い、コンピュータがデータの内容や関係性を理解・処理できるようにする仕組みを指し、それこそ「知識同士が論理的に結びつく世界」を目指している分野である。
そうした応用を目指し、あらかじめ保有する膨大な文書データからナレッジグラフを作成する試みがある[1-3]。しかし、テキストからナレッジグラフを構築する過程では、常に表記・表現の揺れの適切な統合が課題となる。単にフレーズ埋め込みを使い、DBSCANなどのクラスタリング手法でグルーピングを試みても、経験的にうまく機能しない場合が多い。例えば、「景気が上向く」と「景気が下向く」のように、同一視してはいけないフレーズがひとまとまりになることがある。また、「新型コロナウイルス」のように強い印象を持つ単語を含む場合、ほぼすべてのバリエーションがそのクラスタに含まれてしまうこともある。Universal Sentence Encoder[4]、Glucose[5]、Sentence Transformer[6]、Ruri[7]など、埋め込み手法を変更しても大きな改善には至らず、クラスタリング手法をK平均法や階層クラスタリングに切り替えても状況は大きく変わらない。依然として、適切な構造化を達成することは困難なままとなっている。
無論、大規模自然言語モデルの能力に頼る手もある。2つの表現を提示し、「次の表現は同等と判断できるか?」と尋ねれば、人間による判断とさほど変わらない精度に到達できる。しかし、仮に100万個のユニークな表現が存在する場合、それらをペアワイズで比較するには約10¹²回の評価が必要になる。2025年現在、それなりにAPIコストが発生する状況下で、そのような比較を行うことは現実的ではない。仮にAPIコストがほぼ0になったとしても、やはり積極的に試みたいとは思えない。
2. 本稿の目的
そこで、ここでは表現埋め込みとクラスタリングの結果を踏まえ、大規模言語モデルを用いた表記・表現の揺れを適切に統合する方法を簡単に紹介する。データには内閣府景気ウォッチャー調査を活用する。ここに掲載した分析は[1]の中小企業白書のコラムで紹介した方法の元となるものである。本稿を超えてどういう分析をしたかはそちらを参照していただきたい。手法の要点を簡潔にまとめると次のとおりになる。
表現吸収のステップ
(1) 抽出したフレーズ一覧について表現埋め込みを計算し、DBSCANでクラスタリングする。
(2)一定数以上の表現が含まれるクラスタに対して、既存のクラスタ情報(最初は空)と表現を100個ずつLLMに渡し、クラスタリングを指示する。
(3)作成されたクラスタ、最初のクラスタリングステップでクラスタリングされなかった表現、(2)でクラスタリングされなかった表現の統合可能性を再度LLMに確認する。
といった流れである。詳細なコードは[8]にあるので参照してほしいが、これによって単に埋め込みとDBSCANを用いた結果よりは、はるかに良い結果が得られることを示す。
3. 検証に用いるデータ
本稿では[1]に詳細を記した内閣府景気ウォッチャー調査を用いる。内閣府の景気ウォッチャー調査は、全国の景気に敏感な職場で働く人から、景気の現状や先行きを5段階評価とコメントで聴取し、景況感指数(DI)を算出することで、地域ごとの景気動向を的確かつ迅速に把握するための調査である。具体的には
「2020年2月;近畿;その他非製造業[衣服卸](経営者);・最近の新型コロナウイルスの悪影響も懸念されるが、既に中国政府の発表で、中国からの輸出の減少がしばらく続くことが予想される。これに伴い、納期の遅れや、販売時期の繰り下げといった、実質的な影響や混乱が生じつつある。業界では、悪い材料が多過ぎるとの見方が大半を占める。;□」
というものである。この「□」は景気の現状に関する5段階評価の判断指標を示しており、本コラムにおいては、景気状況を良好と評価する順に「◎」に5点、「○」に4点、「□」に3点、「▲」に2点、「×」に1点という数値を割り当てて分析を行っている。
これらを[8]に記したプロンプトを用いて、図1のように因果関係にまとめる。昨今のLLMsの性能は非常に高い。稀にこの段階でも幻覚を起こし、本来回答中に現れない内容を出力することがあるが、プロンプトに「”expressions” に記載する際の表現は、必ず入力の表現と一言一句完全に一致していなければなりません。わずかな改変も行わないようにし、表現の出だしがほぼ同じであっても勝手に省略しないでください。この後の処理は人間ではなく機械が行うため、厳密な一致が求められます。」と記すことで、最終的に原因と結果を記したフレーズが元の文章に存在していたかの確認をある程度容易にできる。その反面元の文の中の表記・表現の揺れはそのまま残ることになる。本稿の話題となるのは、この原因と結果に出現したフレーズの表記・表現の揺れの適切な統合である。
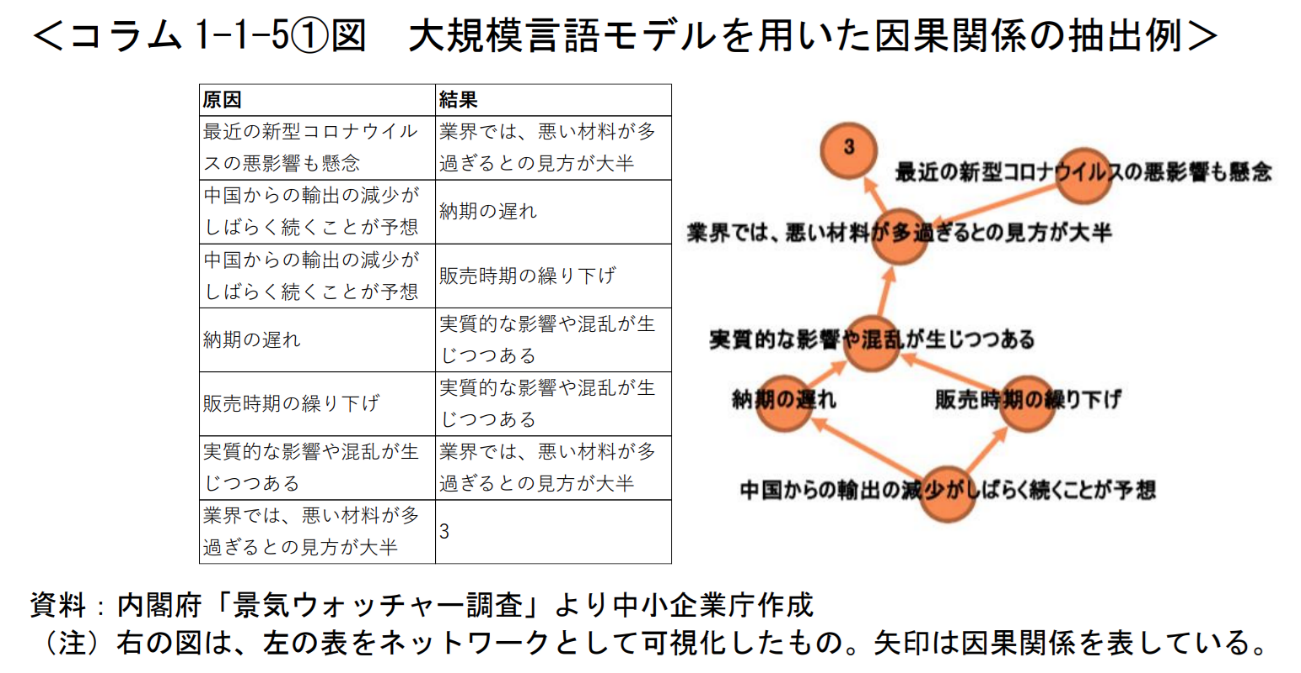 図1:[1]より転載
図1:[1]より転載
最初に上記ステップ(1)を実行する。具体的には、Glucoseを用い、DBSCANについては[9]で示されているコードを使用した。この中の最大クラスタに含まれる表現をまとめたものが表1のラベルで同一となっているものである。確かに「新型コロナウイルス感染症」に関連する内容が集まってはいるが、「新型コロナウイルスの出口がなかなか見通せない」、「感染者数が落ち着きをみせ始めている」、「感染力の強い新型コロナウイルスの変異株の出現」を同一視してしまうのは分析上問題がある。こういった表現は、ポジティブ・ネガティブといった極性値による分類でも限界がある。経済データにおいては、円安と円高で意味がまったく異なるため、特に極性に敏感になる必要がある。このままでは、景気ウォッチャー調査での活用は難しい。

表1:ステップ(1)の直後の結果で同一クラスタに含まれる表現の一部。
ここで重要になるのがステップ(2)となる。発想としては、ベイジアンノンパラメトリクスに近い。ベイジアンノンパラメトリクスで使用される代表的な確率過程(中華料理店過程)は、次のように表記できる。
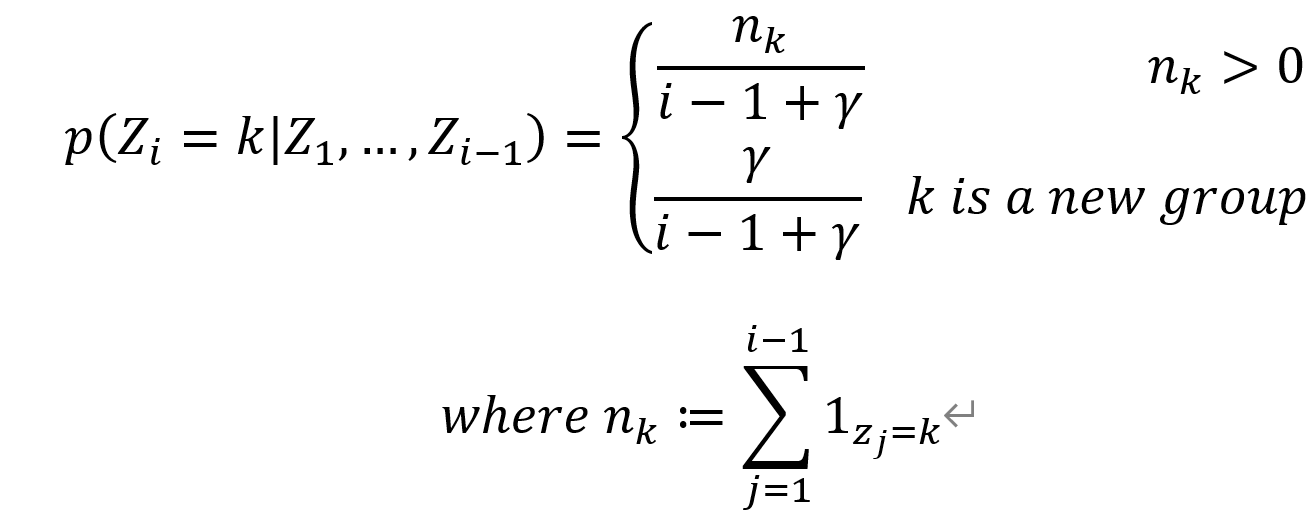
ここでZ_iはi番前のデータが所属するクラスタを差し、γはハイパーパラメータである。
新しいデータに対して、各クラスタのサイズに比例して所属先を決める一方で、新規クラスタが生まれる可能性も残す仕組みとする。本稿では、既存クラスタの大きさに比例する部分をLLMsに置き換える点がポイントとなる。つまり、クラスタへの所属は、各クラスタの代表表現をLLMsに与えて判断させ、適切なクラスタが見つからない場合は新規クラスタに加えるということである。100個ずつLLMsに渡すのは、プロンプトとして扱える情報量の限界に対応するための措置である。
理想的にはこれで完璧に仕上がってほしいところだが、LLMsは大量にプロンプトを投入すると、すべての表現に対して出力を返さない傾向がある。さらに、そもそもステップ(1)の段階で、本来ひとつにまとまるべきクラスタが分かれてしまったり、DBSCANの性質上、アウトライアーとして捉えられてしまったりする表現も存在する。そこで、最後に行うのがその補正となる。詳細はコード[8]を参照されたい。
4. 結果
この手法による(1)の時点との比較では、クラスタリングの改善を確認するため、前述の表1でも利用した最大クラスタに注目する。表2に分割結果を示す。「新しいラベル」はステップ(2)および(3)を経た後のものであり、各クラスタには可読性を高める目的で代表表現を記載した[10]。新型コロナウイルス感染症に関するデータが混在していた状態から、明確に分類できるようになったことがわかる。単純な変化にとどまるが、この段階で初めてグラフ構造に基づく分析が可能となる。
この結果をもとに描いたのが図2となる。景気ウォッチャー調査に基づくため、最終的には1から5までの景況値に収束する流れとなる。景況判断に対応するかたちで、それぞれの表現が大きなクラスタにまとまっている様子が見て取れる。重要なのは、2017年時点では新型コロナウイルス感染症に関連する表現が存在しなかった一方で、2020年時点では主にネガティブな影響が目立つようになり(左下)、2021年にはポジティブな話題(「新型コロナウイルスの5類感染症への移行」)も加わった点にある。こうした微妙な変化は従来の方法では整理が難しかったが、今回の手法によってきれいにまとめられるようになったことが確認できる。
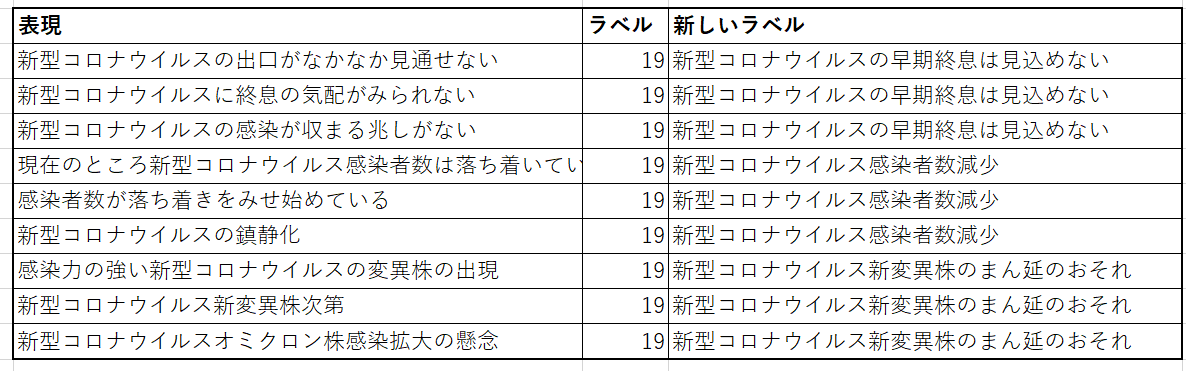
表2:ステップ(2)と(3)の後の表記・表現の揺れの解消具合を示した表。
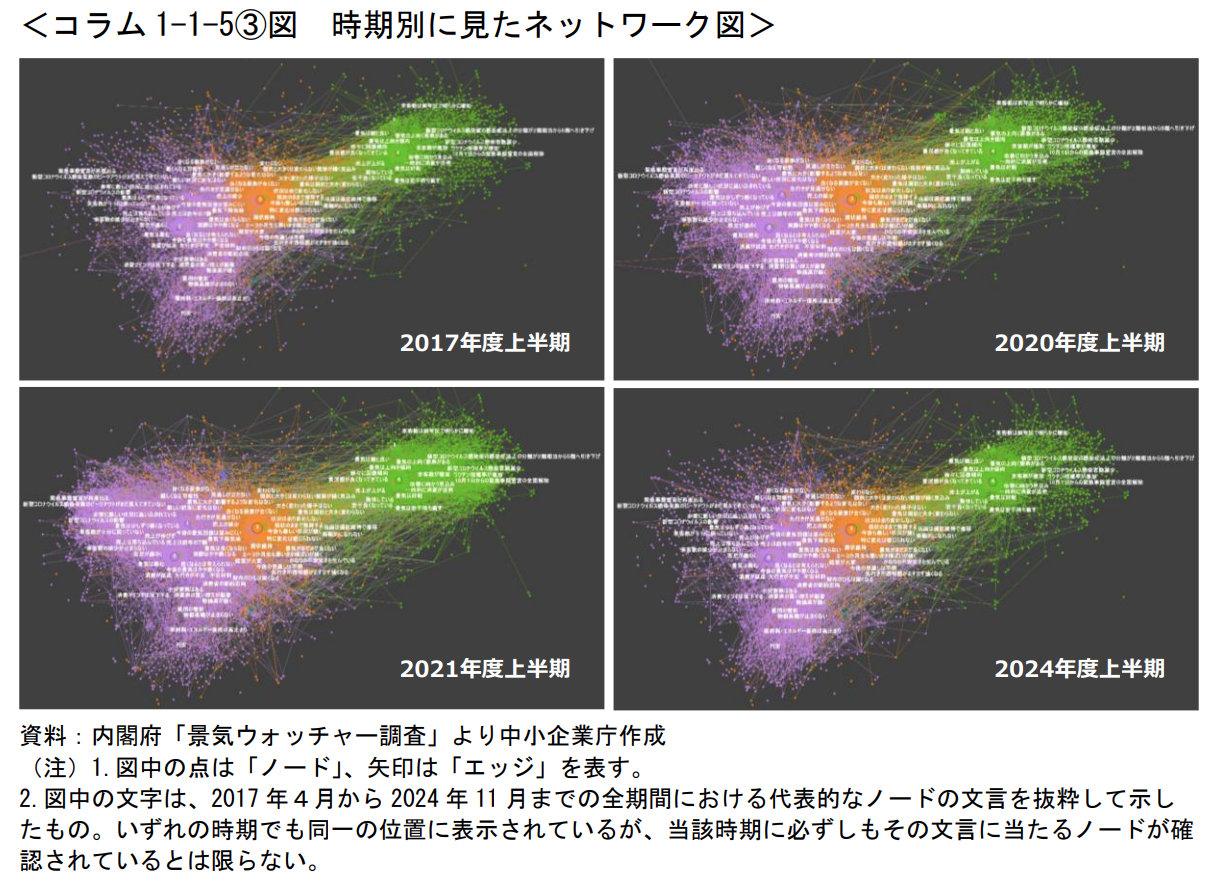 図2:[1]より転載。詳細な図を見たい場合はhttps://www.rhisano.com/figuresを参照。
図2:[1]より転載。詳細な図を見たい場合はhttps://www.rhisano.com/figuresを参照。
5. まとめ
本コラムでは、表現揺れの問題に対し、LLMsを活用した手法を紹介した。内閣府景気ウォッチャー調査のデータを用い、単純な埋め込みとクラスタリングだけでは捉えきれなかった表現の微妙な違い(たとえば「新型コロナウイルスが終息傾向」と「新型コロナウイルスの脅威が高まっている」)を、LLMsを通じて適切に分類し、分析精度を高める取り組みを解説した。
表現揺れの吸収は一見単純な作業に見えるが、これをうまく処理できなければ、最終的にきれいなネットワークを構築することは難しい。実際、こうした単純に見えるが従来技術では解決が難しい問題が、[1]で記したような分析や、Graph RAGの幅広い応用における大きな障壁となってきた。些細に思える課題であっても、LLMsを活用することで突破口を開き、分析や応用の可能性を広げることができる。
6. 謝辞
本稿の執筆にあたり、中小企業庁事業環境部調査室に多大な支援を受けた。ここに感謝の意を表する。
参考文献
[1] 2025年版「中小企業白書」、 コラム1-1-5「テキストデータを活用した景気判断と消費動向変化の把握」、https://www.chusho.meti.go.jp/pamflet/hakusyo/2025/PDF/chusho/10Hakusyo_column_web.pdf
[2] Kondo, R., Watanabe, T., Yoshida, T., Yamasawa, K., & Hisano, R. (2024). Collaborative System Synergizing Human Expertise and Large-scale Language Models for Legal Knowledge Graph Construction. ISWC 2024 Posters and Demos: 23rd International Semantic Web Conference, November 2024.
[3] Matsuoka, R., Matsumoto, H., Yoshida, T., Watanabe, T., Kondo, R., & Hisano, R. (2024). Hierarchical Narrative Analysis: Unraveling Perceptions of Generative AI. Proceedings of Jinmoncon 2024, IPSJ SIG Computers and the Humanities, December 2024.
[4] Cer, D., Yang, Y., Kong, S.-Y., Hua, N., Limtiaco, N., St. John, R., Constant, N., Guajardo-Cespedes, M., Yuan, S., Tar, C., Sung, Y.-H., Strope, B., & Kurzweil, R. (2018). Universal Sentence Encoder. arXiv preprint arXiv:1803.11175.
[5] Armandpour, R., Azhir, A., & Rabiee, H. R. (2021). Deep Personalized Glucose Level Forecasting Using Attention-Based Recurrent Neural Networks. arXiv preprint arXiv:2106.00884.
[6] Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv preprint arXiv:1908.10084.
[7] Tsukagoshi, H., & Sasano, R. (2024). Ruri: Japanese General Text Embeddings. arXiv preprint arXiv:2409.07737.
[8] https://github.com/hisanor013/HierarchicalNarratives
[9] Xu, H., & Pham, N. (2024). Scalable DBSCAN with Random Projections. Advances in Neural Information Processing Systems, vol. 37, pp. 27978—28008, Dec 2024.
[10] クラスタ内の表現のうちもっとも中心に近いものをその代表表現としている。





